垂直数据存储
利用序列优化数据访问
SmartEDB 序列数据类型提供了以垂直或列式形式存储数据的能力。序列是 SmartEDB 支持的标量数据元素(即 [u]int[1|2|3|4]、时间、日期、单精度浮点数、双精度浮点数、字符和日期时间)的无界数组。序列是动态的;它们无需通过字典进行布局放置,并且可以在运行时创建和删除。数据库模式定义了序列字段,并且对于有序序列,定义了序列是升序还是降序。
应用程序通过其句柄访问序列,其性质类似于 SmartEDB 对象句柄。在类中的多个序列可被当作一组来处理,这实际上形成了一个时间序列。有关实现详情,请参阅“使用序列”页面。另外还提供了一个分析函数库,可对序列执行各种操作和统计计算。
考虑以下示例:
class Quote {
char<8> symbol;
char<8> exchange;
sequence<time asc> timestamp;
sequence<float> bid;
sequence<float> ask;
sequence<uint4> volume;
hash<symbol> by_sym[1000];
};此示例定义了一个名为 Quote 的类,该类具有一个名为 symbol 的字段,每个此类对象中该字段仅出现一次,并通过名为 by_sym 的哈希索引强制其值唯一。该类包含一个时间序列,由六个序列组成。时间序列应按照时间戳升序处理。
注意:SmartEDB 不会对升序或降序序列中的元素进行排序。升序/降序修饰符会使 SmartEDB 确保数据按正确的顺序插入,若未按此顺序插入则会返回错误,并且会使模式编译器为有序序列生成额外的函数。
列式布局与行式布局
从概念上讲,序列可以被视为以列的形式组织起来。
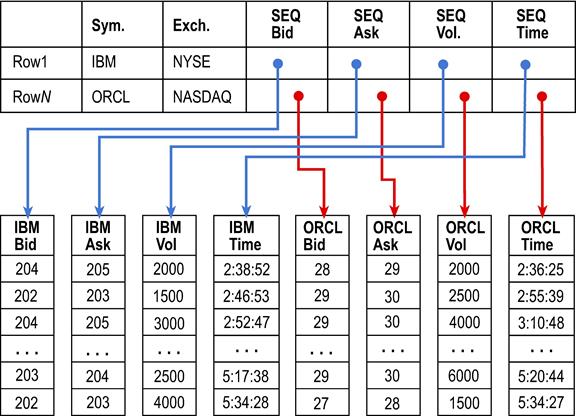
因此,对于序列,SmartEDB 是传统行式数据库和列式数据库的混合体。“常规”的类/表字段/列以传统的行式方式存储,这对于通常的数据处理需求来说是自然且高效的。然而,序列则以垂直或列式布局存储,当数据处理模式需要对一个或多个列的大量值进行迭代时,这种方式要高效得多。在列式布局中,数据库页面(数据库系统中的存储单元)仅包含该列的值,而不包含其他列的值。其优势在于数据库系统不会浪费处理周期来检索不需要的数据,而行式布局则会如此。换句话说,如果一个页面包含 40 行表数据,每行有 15 列,但处理任务只需要 1 列,那么对于数据库管理系统读取的每个页面,只有约 6.7% 的页面读取数据是有用的;其余的都被丢弃。(该页面有 40×15 = 600 个值,其中只有 40 个值用于处理,约占 6.7%。)相反,采用列式布局时,数据库页面仅包含该列的值,因此读取页面时传输的 100% 数据都是有用的,不存在浪费。
序列可以是有序的(如上面的“时间戳”),也可以是无序的(如上面的其他序列)。有序序列可以通过值进行搜索,否则只能通过索引(即通过序列中的位置)进行搜索。升序属性不会指示运行时对输入数据进行排序。相反,运行时会检查数据是否按正确顺序插入,如果不是则返回错误。
序列的并行处理
在多处理器环境中,通过 SmartESQL 中的线程池管理可以实现进一步的性能优化。
详情请参阅“使用序列的并行处理”页面。
有关序列的使用和实现的详细信息,请参阅“使用序列”页面。