分布式SQL引擎
SmartESQL 分布式 SQL 引擎为 SmartEDB 集群的分片架构提供有限支持。原因在于,大多数成熟的分布式数据库引擎(如 Oracle)会基于查询树和数据分布统计信息创建包含“映射-归约”操作的执行计划。而 SmartESQL 分布式引擎仅在每个节点上执行查询,并在可能的情况下合并多个节点的结果集。
有时合并结果集无法实现,例如计算平均值时。更多情况下,引擎缺乏足够的信息来确保合并后的结果集正确。因此,分布式 SQL 引擎采取乐观策略,假设应用程序已合理分布数据并编写了避免合并问题的 SQL 查询。
尽管存在局限性,许多应用程序仍能通过使用分布式引擎显著提升数据库访问性能。
分布式 SQL 引擎可以将查询发送到单个节点或广播至所有节点,具体节点通过查询前缀指定。为了控制数据分布,应用程序可以在本地加载数据到每个分片,或在插入语句中指定节点 ID。例如:
10:insert into T values (...)此外,应用程序在选择特定节点上插入的记录时,也可以明确地在选择条件中使用当前节点 ID(%# 表示当前节点 ID,%@ 表示分片数量)。例如:
insert into hist_cpvehicleid_jj
select * from foreign table (path='/home/usr/shea2.csv', skip=1)
as hist_cpvehicleid_jj
where mod(hashcode(fstr_vechileid), %#)=%@;如果未使用上述任何一种方法,分布式 SQL 引擎将在所有节点上广播插入操作。支持以下查询类型:
select * from T;
*:select * from T; -- similar to the above, run the statement on all nodes
N:select * from T; -- execute the statement on the node N (nodes are enumerated from 1)
?:select * from T; -- execute the statement on any node. SQL picks up the node
in the round-robin fashion, thus implementing a simple
load-balancing scheme通常情况下,select、update 和 delete 语句会在所有节点上执行,而 insert 语句仅向一个分片添加记录。查询执行并生成结果集后,分布式 SQL 引擎会从所有节点收集数据。如果查询包含聚合、排序子句或序列函数(对序列类型字段操作的统计函数),则会合并结果集。
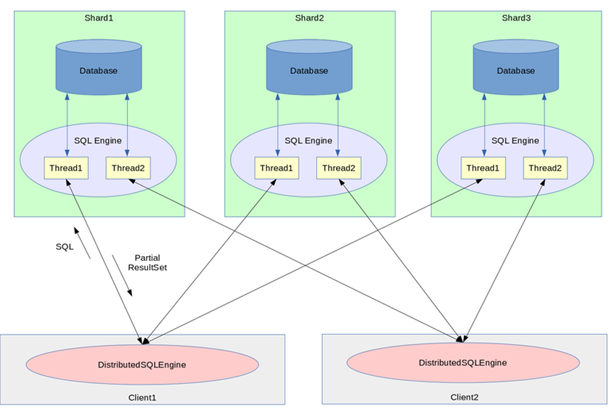
下图展示了分布式 SQL 引擎的数据流。请注意,shard1、shard2、shard3、client1 和 client2 可以分布在不同的物理主机上,也可以在同一台主机上,或者以任意组合形式存在。例如,shard1、shard2 和 client1 可以位于一个物理节点上,而 shard3 和 client2 位于另一个物理节点上。
聚合函数
分布式 SQL 引擎目前支持以下聚合函数:
- COUNT
- MIN
- MAX
- SUM (聚合操作数为列),带或不带“GROUP BY”子句
引擎当前不支持:
- 使用 DISTINCT 限定符合并聚合;
- 对复杂表达式(如 X+Y)进行聚合,除非排序列或分组列包含在结果集中或选择语句中;
例如(以 Metatable 为例):
select Metatable.*,FieldNo+FieldSize as ns from Metatable order by ns;或
select T.*,x+y as xy from T order by xy;除了两种情况外,基于哈希的聚合(seq_hash_aggregate_*):
当哈希表所基于的数据属于单个分片(如下例中的交换)时:
select seq_hash_agg_sum(price,exchange) from Quote;如果将序列转换为水平表示形式——展平,那么查询就可以在任何数据分布的情况下运行:
select flattened seq_hash_agg_sum(price,exchange) from Quote;
AVG 聚合。除非来自不同节点的组不重叠。例如,以下布局是受支持的:
Node1:
Symbol Price
AAA 10.0
AAA 12.0
AAA 9.0
BBB 11.0
BBB 10.0
BBB 10.0
Node2:
Symbol Price
CCC 8.0
CCC 7.0
CCC 10.0
DDD 15.0
DDD 14.0
DDD 13.0
select avg(Price) from Quote group by Symbol;其他有效和无效陈述的例子有:
select * from T;支持;结果被连接起来。
select * from T order by y;支持;从所有节点对结果进行排序。
select * from T order by x+y;目前不支持复杂表达式。
select sum(x) from T;支持;汇总的结果被合并。
select avg(x) from T;AVG 聚合的合并目前不受支持。
select y,sum(x) from T group by y;支持;组和聚合被合并。
select sum(x) from T group by y;支持;请注意,“分组依据”的列必须包含在“from”列表中。
select sum(x*2) from T;目前不支持复杂表达式。
select ifnull(sum(x), 0) from T;支持;汇总结果已合并。
select seq_sum(x) from T;支持;结果已合并。
select seq_hash_agg_sum(x,y) from T;当前不支持哈希聚合的合并。
select flattened seq_hash_agg_sum(x,y) from T;支持;已排序、分组并汇总。
数据导入
分布式 SQL 引擎支持在从 CSV 文件导入数据或通过应用程序代码导入数据时定义分片条件。通过以下 SQL 语句指定 CSV 导入数据的分片:
select from foreign table (path='csv-file', skip=n) as PatternTable where distribution-condition分发条件包含:
- 一个插入-选择语句,
- 一个指定 CSV 文件名的 FROM 子句,
- 一个指定要插入的表的 AS 表达式,
- 以及一个指定目标节点的 WHERE 子句。
如上所述,分布式 SQL 引擎还支持特殊的“%@”和“%#”伪参数。前者对应节点编号(从零开始);后者用于指定节点总数。例如:
echo "insert into table_name
select * from foreign table (path='table_name_file.csv', skip=1) as table_name
where mod(instrument_sid/$chunk_size,%#)=%@;" > loadrisk.sql
./xsql.sh loadrisk.sqlxsql.sh 脚本按如下方式调用分布式 SQL 引擎:
xsql @node1 @node2 ... @nodeN $@应用程序可以从流(如下例中的套接字)或任何其他来源读取输入数据,并通过类似于以下代码片段的代码将其插入数据库:
table_name tb;
socket_read(s, &tb);
engine.execute("insert into table_name(starttime, endtime,
book1, book2, instrument_sid)
values (%l,%l,%s,%s,%l)",
tb.starttime, tb.endtime,
tb.book1, tb.book2, tb.instrument_sid);以下代码片段会向应用程序的代码中添加一个分片条件:
char sql[MAX_SQL_STMT_LEN];
table_name tb;
socket_read(s, &tb);
sprintf(sql, "%d:insert into table_name (starttime,endtime,book1,book2,instrument_sid)
values (%%l,%%l,%%s,%%s,%%l)", tb.instrument_sid%n_nodes);
engine.execute(sql, tb.starttime, tb.endtime, tb.book1, tb.book2, tb.instrument_sid);在运行时添加分片
有时可能需要向现有的分布式网络添加一个分片,例如从 3 个分片增加到 4 个。为此,所有客户端都需要重新连接到这 4 个分片。这就需要关闭连接到 3 个分片的分布式 SQL 引擎,并重新连接到全部 4 个分片。
移动或重新平衡数据是应用程序的责任,因为没有一种正确的方法可以自动在分片之间重新分配数据。本质上,必须将数据拉取到客户端,然后从该客户端重新分配。
一种方法是使用文件来输出数据。例如,将 xSQL 客户端的数据输出到外部文件:
XSQL>format CSV
XSQL>output mytable.csv
SELECT * FROM MYTABLE现在,文件 mytable.csv 已被复制到所有分片,并插入到相应的表中:
XSQL>INSERT INTO MYTABLE from select * from foreign table (path='mytable.csv') where ...另一种可能的方法是使用以下语义从位于节点 1 的表 T 中选择数据并将其插入到节点 2 上的表 T 中:
XSQL>create table foo(i integer, s varchar);
XSQL>1:insert into foo values (1, 'one');
XSQL>1:insert into foo values (2, 'two');
XSQL>select * from foo;
i s
----------------------------------------------------------------------
1 one
2 two
Selected records:2
XSQL>1:select * from foo;
i s
----------------------------------------------------------------------
1 one
2 two
Selected records:2
XSQL>2:select * from foo;
i s
----------------------------------------------------------------------
Selected records:0现在在节点 2 中向表 foo 插入一个新对象,然后使用“1>2”语法将节点 1 中表 foo 的内容插入到节点 2 中,并显示结果,首先是两个节点的聚合结果,然后是各个节点的结果:
XSQL>2:insert into foo values (3, 'three');
XSQL>1>2:select * from foo;
XSQL>select * from foo;
i s
----------------------------------------------------------------------
1 one
2 two
3 three
1 one
2 two
Selected records:5
XSQL>1:select * from foo;
i s
----------------------------------------------------------------------
1 one
2 two
Selected records:2
XSQL>2:select * from foo;
i s
----------------------------------------------------------------------
3 three
1 one
2 two关于分片条件的说明
为了使应用程序从分片中获益,通常需要满足以下条件:
- 数据规模足够大:数据量应达到数十 GB 以上,以便搜索算法(如树查找和哈希索引)能从减少的数据集中显著获益。
- 硬件支持并行处理:每个分片的访问应由独立的 CPU 核心处理,并且 I/O 通道应分开。如果分片在同一主机上,分片数量应等于实际 CPU 核心数,存储介质应采用 RAID 布局。
分片并非没有代价。尽管理论上可以从原生 SmartEDB API 利用分片,但实际操作中几乎不这样做,因为应用程序很难高效合并分片结果集。分布式 SQL 引擎通过创建执行计划来实现这一功能,但其支持的 SQL 查询范围有限,某些操作(如 JOIN)可能需要在所有分片上复制数据,导致较大的内存和存储开销。因此,分布式 SQL 引擎更适合资源充足的服务器环境,具有大量 CPU 内核、内存和分布式 I/O 子系统。
嵌入式环境中(如 INTEGRITY OS、VxWorks OS),由于资源受限,使用分布式 SQL 引擎通常无法带来明显收益。如果确实需要,可以根据具体需求定制分发包。
对不同主机语言的支持
除了 C 和 C++ 语言之外,分布式 SQL 引擎还可以从 Java、C# 和 Python 语言中使用。
Java
要在 Java 中创建分布式连接,只需通过调用以下构造函数重载来实例化一个 SqlRemoteConnection 对象:
/**
* Constructor of the distributed database connection.
* @param nodes database nodes (each entry should have format "ADDRESS:PORT")
*/
public SqlRemoteConnection(String[] nodes, int maxAttempts)
{
engine = openDistributed(nodes);
}例如,以下代码片段在两个节点上打开分布式 SQL 引擎以进行分片:
static String [] nodes = new String[]{"localhost:40000", "localhost:40001"};
SqlRemoteConnection con = new SqlRemoteConnection(nodes);请注意,运行时初始化是在 Database 类的构造函数中完成的,因此即使不使用,也必须创建一个 Database 对象。
C# (.NET Framework)
要在 C# 中创建分布式连接,只需通过调用以下构造函数重载来实例化一个 SqlRemoteConnection 对象:
/**
* Constructor of the distributed database connection.
* @param nodes database nodes (each entry should have format "ADDRESS:PORT")
*/
public SqlRemoteConnection(String[] nodes)
{
engine = OpenDistributed(nodes);
}例如,以下代码片段在两个节点上打开分布式 SQL 引擎以进行分片:
static String [] nodes = new String[]{"localhost:40000", "localhost:40001"};
SqlRemoteConnection con = new SqlRemoteConnection(nodes);请注意,运行时初始化是在 Database 类的构造函数中完成的,因此即使不使用,也必须创建一个 Database 对象。
Python
要使用 Python 创建分布式连接,请以元组作为第一个参数打开模块方法 connect。例如:
con = exdb.connect(('node1:5001', 'node2:5001', 'node3:5001'))还可以使用 Python 包装器创建 SQL 服务器。例如:
conn = exdb.connect("dbname")
# pass engine, port and protocol buffer size.
# Note that 64K is not enough if sequences are used
server = exdb.SqlServer(conn.engine, 50000, 64*1024)
server.start() # Non-blocking call
... # Do something else or just wait
server.stop() # Stop server
conn.close()xSQL 分片
为了说明如何使用 xSQL 与分布式 SQL 引擎,考虑以下数据库模式(通过 SQL 创建):
create table Orders (
orderId int primary key,
product string,
customer string,
price double,
volume doulbe
)以及文件 order.csv 中的以下 CSV 数据:
orderId|product|customer|price|volume
1|A|james|10.0|100
2|B|bob|50.0|200
3|A|paul|11.0|300
4|C|paul|100.0|150
5|B|bob|52.0|100
6|B|bob|49.0|500
7|A|james|11.0|100
8|C|paul|105.0|300
9|A|bob|12.0|400
10|C|james|90.0|200创建 SQL 服务器
首先,要创建几个数据库并在其上运行 SQL 服务器,我们使用 xSQL 的命令行参数如下,创建三个大小为 10MB 的内存数据库实例,并启动 SQL 服务器分别监听 10001、10002 和 10003 端口:
./xsql -size 10m -p 10001
./xsql -size 10m -p 10002
./xsql -size 10m -p 10003现在,我们可以使用分布式 SQL 引擎连接到所有三个服务器,因为 xSQL 接受服务器地址作为命令行选项:
./xsql @127.0.0.1:10001 @127.0.0.1:10002 @127.0.0.1:10003或者,我们可以在配置文件(client.cfg)中指定服务器地址,如下所示:
{
remote_client : [ "127.0.0.1:10001", "127.0.0.1:10002","127.0.0.1:10003"]
}并按如下方式调用 xSQL:
./xsql -c client.cfg
使用 xSQL 交互模式
连接到服务器后,xSQL 进入交互模式。首先,我们使用以下命令在所有节点上创建一个表:
create table Orders (orderId int primary key, product string,
customer string, price double, volume double);默认情况下,分布式 SQL 引擎会将查询发送到所有节点。因此,创建表的语句将在所有三个节点上执行。接下来,我们可以使用以下 SQL 语句导入数据并在服务器之间进行分布:
insert into Orders select * from 'order.csv' as Orders where mod(orderId, %#)=%@;伪参数“%#”和“%@”分别表示节点总数和基于零的节点 ID。在我们的例子中,“%#”等于 3,而“%@”对于第一个服务器(运行在端口 10001 上)为 0,对于第二个服务器为 1,对于第三个服务器为 2。例如,在第二个服务器上,该语句将等同于:
insert into Orders select * from 'order.csv' as Orders where mod(orderId, 3)=1;因此插入了 ID 为 1、4、7 和 10 的订单。(请注意,如果您在不同的主机上启动 SQL 服务器,则文件 order.csv 必须在所有主机上均可访问。) 现在,为了检查数据,我们从所有节点选择记录:
XSQL>select * from Orders order by orderId;
orderId product customer price volume
------------------------------------------------------------------------------
1 A james 10.000000 100.000000
2 B bob 50.000000 200.000000
3 A paul 11.000000 300.000000
4 C paul 100.000000 150.000000
5 B bob 52.000000 100.000000
6 B bob 49.000000 500.000000
7 A james 11.000000 100.000000
8 C paul 105.000000 300.000000
9 A bob 12.000000 400.000000
10 C james 90.000000 200.000000
Selected records: 10仅从第二台服务器选择记录:
XSQL>2:select * from Orders;
orderId product customer price volume
------------------------------------------------------------------------------
1 A james 10.000000 100.000000
4 C paul 100.000000 150.000000
7 A james 11.000000 100.000000
10 C james 90.000000 200.000000使用group by和order by语句:
XSQL>select product, sum(price*volume) as s from Orders group by product;
product s
------------------------------------------------------------------------------
A 10200.000000
B 39700.000000
C 64500.000000
XSQL>select customer, sum(price*volume) as s from Orders group by customer order by s;
customer s
------------------------------------------------------------------------------
james 20100.000000
bob 44500.000000
paul 49800.000000使用表限定符
目前,分布式客户端应用程序无法在“ORDER BY”或“GROUP BY”列列表中使用表限定符作为前缀。例如,给定一个名为“Customer”的表以及一个名为“LastName”的列,其定义的模式如下:
class Customer
{
uint4 customerKey;
string FirstName;
string LastName;
hash<customerKey> by_customerKey[500000];
};
class Facts
{
uint4 customerKey;
double price;
uint4 Quantity;
tree<customerKey> by_customerKey;
};以下选择语法不受支持:
SELECT customer.FirstName, customer.LastName, sum(facts.Quantity) as qty,
sum(facts.price) as price, as sales
FROM customer, facts
GROUP BY customer.FirstName, customer.LastName
ORDER BY customer.FirstName, customer.LastName;也不支持其他语法,例如以下这种(使用别名)的语法:
SELECT supplier.address as s_address, customer.address as c_address
FROM supplier, customer
ORDER BY s_address, c_address;也不支持其他语法:
SELECT supplier.address, customer.address
FROM supplier, customer
ORDER BY 1, 2;