产品概述
SmartESQL 在 C 库 libmcosql 中实现。C 和 C++ 开发人员可直接将这些库链接到其应用程序中,并能使用 C 语言 API 函数,例如 mcosql_execute_query() 和 mcosql_execute_statement(),或者丰富的 C++ 类,例如用于执行 SQL 语句和查询的 McoSqlEngine 以及用于处理结果集的 QueryResult。Java、C# 和 Python API 也通过类 SqlLocalConnection、SqlRemoteConnection 和 SqlResultSet 支持 SQL。
此外,还提供了高度可配置的命令行实用工具 xSQL,以便在 SmartEDB 数据库上以交互方式或通过 SQL 脚本文件开发和测试 SQL 脚本,涵盖所有可能的选项,包括 MVCC 或 MURSIW 事务管理器、调试或发布库、SmartEDB 高可用性和 SmartEDB 集群。快速入门教程提供了演示 xSQL 使用方法的示例。
SmartESQL 是一种高性能的 SQL 实现,是基于 SmartEDB 的卓越性能和针对内存数据库优化的 SQL 引擎,能够快速处理动态 SQL 查询。使用 SmartESQL 的优势包括:
- 与原生 SmartEDB 共存:在同一应用程序中结合使用 SmartESQL 和 SmartEDB API。对于关键性能需求,SmartEDB API 提供最佳性能;对于复杂查询和聚合操作,SmartESQL 提供更高层次的访问。
- 广泛支持 SQL-89 标准:实现大部分 ANSI SQL-89 规范。
- 扩展特性:支持结构体、数组和向量等 SmartEDB 特定数据类型,并基于 SmartEDB 功能进行查询优化。
- 全面兼容性:与所有 SmartEDB 版本(API、事务日志、高可用性和集群)完全兼容,无需担心迁移问题。
- 嵌入式架构:作为应用程序的一部分嵌入,消除客户端/服务器通信开销,提升性能并简化管理。
- 交互式工具:提供强大的 xSQL 工具,用于管理和测试 SmartEDB 数据库中的 SQL 语句。
的数据进行操作(如添加、更改或删除)。
操作概述
以下图表说明了 SmartESQL 应用程序的结构和操作流程:
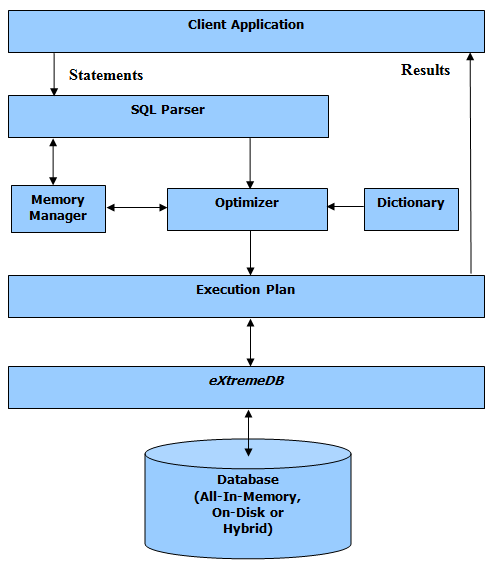
此图描绘了 SmartESQL 的主要操作步骤和元素。SQL 语句嵌入在应用程序代码中,并通过上述 API 提交给 SmartESQL。这些 SQL 语句会被解析以验证其语法正确性。然后,如果未发现错误,就会调用优化器。优化器会通过查询数据库字典来尝试确定处理该语句的最有效方式,以发现潜在的索引以及类之间的自动标识符/引用关系。此步骤会产生一个执行计划,该计划确定 SmartESQL 为生成结果集所要采取的过程步骤(例如,通过字段 A 的索引定位类 X 的对象;将找到的对象的字段 B 的值作为类 Y 的索引字段 D 的搜索值,等等)。
在语句经过解析、优化并形成执行计划之后,数据库会被更新或查询。
SmartESQL 处理
通常情况下,SmartESQL 语句会嵌入到 C、C++、Java 或 C# 中,通过在单线程应用程序中实例化引擎对象并调用其执行方法来实现。不过,多个进程可以同时访问共享内存中的数据库,或者单个进程中的两个或多个线程可以同时访问内存中或基于磁盘的数据库,使用引擎即可。
通过 SmartESQL 访问数据库的并发线程数应谨慎考虑。任何动态 SQL 实现的本质在于,它需要相当广泛地使用动态内存分配,用于解析期间保存标记、执行期间的临时结果以及其他各种用途。为将内存消耗控制在合理范围内,限制同时处理 SQL 的任务(线程)数量是明智之举。
在 SmartESQL 版本 6.5 或更高版本中,已实施了若干重大改进,这些改进解决了复杂 SQL 语句处理方面的性能问题。
具体来说:
- 之前在语句编译和构建执行计划期间发生的动态内存分配已被静态内存“块”分配所取代
- 仅在排序和聚合操作需要时才进行“实体化”
- 对 SmartESQLC++ 和 C API 进行了细微修改,以减少虚拟和间接调用的数量,并在可能的情况下使用数组代替迭代器
- 数据库元数据在会话之间共享,以避免缓存
- 使用当前内存分配器的引用以消除使用线程特定内存的情况。
SmartESQL 查询优化
为 SQL 语句的执行创建最优计划是一项非常复杂且具有挑战性的任务。SQL 优化器会分析发送到数据库的 SQL 查询,并选择访问数据库的最佳搜索策略。
SQL 优化器分为两类:基于成本的和基于规则的。基于磁盘的数据库系统通常使用基于成本的优化器。对于基于成本的优化器,查询优化在很大程度上取决于数据分布。通常,优化器会抽取样本,并使用数据库引擎提供的统计信息,以及自行收集的统计信息,来计算候选执行计划的成本。构建最优计划是 CPU 密集型的,且本质上是不可预测的;优化器所花费的时间因查询而异,而且随着数据分布的变化,执行计划在每次调用时也可能发生变化。
为了提供更快且更可预测的性能,SmartESQL 使用基于规则的优化器,使开发人员能够在应用程序中指定查询执行计划。例如,优化器绝不会重新排列查询中的表:连接操作将按照指定表的顺序执行。用于查询优化的其他一些关键规则包括:
- 如果可能的话,会使用索引。
- 每个表都被分配一个序号,代表其在 FROM 列表中的位置。
- 搜索谓词被分解为合取项集,合取项会被排序。因此,会先检查访问序号较小的表的表达式。
- 通过检查子查询表达式的依赖关系来优化子查询的执行。只有当子查询表达式引用了外部作用域中的字段时,才会保存子查询的结果并重新计算。
有关 SmartESQL中查询优化的更多信息,请参阅优化查询性能页面。